Scraper un site simplement avec le plugin chrome Webscraper.io
Aldok
| 4 minutes
NB : cet article est une traduction de la documentation officielle de l’outil dont la source est consultable ici -> https://webscraper.io/documentation/scraping-a-site.
Scraper un site internet avec Web Scraper.io
Commencez par installer le plugin chrome webscraper sur le chrome store (https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn?hl=en) ou sur le site https://webscraper.io/
1. Créer un Sitemap
La première chose à faire lors de la création d’un sitemap est de spécifier l’url de départ. Il s’agit de l’URL à partir de laquelle le scrapping commencera. Vous pouvez également spécifier plusieurs url de départ si le scrapping doit commencer à plusieurs endroits.
Par exemple, si vous souhaitez scraper plusieurs résultats de recherche, vous pouvez créer une url de départ distincte pour chaque résultat de recherche.
Des champs de saisie d’URL supplémentaires peuvent être ajoutés en appuyant sur + à côté de la saisie d’URL. Une fois le plan du site créé, l’onglet URL de départ peut être trouvé en sélectionnant Edit meta data dans le menu déroulant Sitemap sitemap_name.

2. Spécifier plusieurs URL par tranches
Dans les cas où un site utilise la numérotation dans les URL des pages, il est beaucoup plus simple de créer une url de début de plage que de créer des sélecteurs de liens qui permettraient de naviguer sur le site. Pour spécifier une url de plage, remplacez la partie numérique de l’url de début par une définition de plage - [1-100]. Si le site utilise un remplissage nul dans les urls, ajoutez un remplissage nul à la définition de l’intervalle - [001-100]. Si vous voulez sauter certaines urls, vous pouvez également spécifier l’incrément comme ceci [0-100:10].
Utilisez une plage d’url comme http://example.com/page/[1-3] pour des liens comme ceux-ci :
Utilisez une plage d’url avec plusieurs 0 comme http://example.com/page/[001-100] pour des liens comme ceux-ci :
Pour récupérer des contenus par tranche de 10 -> http://example.com/page/[0-100:10] pour des liens comme ceux-ci :
3. Créer des sélecteurs
Après avoir créé un plan du site, vous pouvez commencer à ajouter, modifier et parcourir les sélecteurs dans le panneau Sélecteurs. Les sélecteurs sont ajoutés dans une structure arborescente. Le scraper Web exécutera les sélecteurs dans l’ordre où ils sont organisés dans l’arborescence. Par exemple, il y a un site d’actualités et vous voulez récupérer tous les liens d’articles qui sont disponibles sur la première page. Dans l’image 1, vous pouvez voir cet exemple de site.
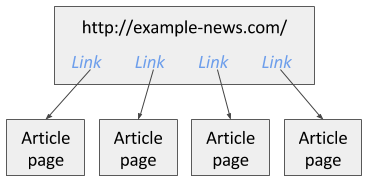
Pour explorer ce site, vous pouvez créer un sélecteur de liens qui extraira tous les liens d’articles de la première page. Puis, en tant que sélecteur enfant, vous pouvez ajouter un sélecteur de texte qui extraira les articles des pages d’articles pour lesquelles le sélecteur de liens a trouvé des liens. L’image ci-dessous illustre la façon dont le plan du site doit être construit pour le site d’actualités.
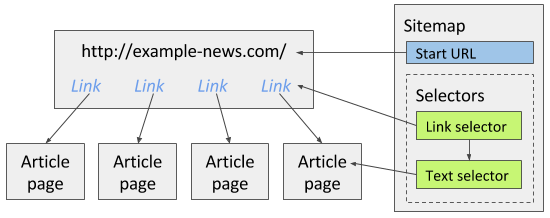
Notez que lors de la création de sélecteurs, les fonctions d’aperçu des éléments et d’aperçu des données permettent de s’assurer que vous avez sélectionné les bons éléments avec les bonnes données. Vous trouverez de plus amples informations sur la construction de l’arborescence des sélecteurs dans la documentation relative aux sélecteurs. Vous devriez au moins lire ces sélecteurs de base :
- Sélecteur de texte
- Sélecteur de lien
- Sélecteur d’éléments
4. Inspection de l’arborescence des sélecteurs
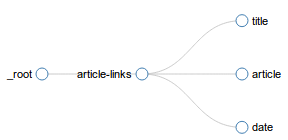
Après avoir créé des sélecteurs pour le plan du site, vous pouvez inspecter l’arborescence des sélecteurs dans le panneau Graphique des sélecteurs. L’image ci-dessous montre un exemple de graphique de sélecteurs.
5. Scraper le site
Une fois que vous avez créé les sélecteurs pour le plan du site, vous pouvez commencer le scraping. Ouvrez le panneau “Scrape” et lancez l’opération. En option, vous pouvez modifier l’intervalle entre les requêtes et le délai de chargement des pages.
Une nouvelle fenêtre popup s’ouvre, dans laquelle le scraper charge les pages et en extrait les données. Une fois l’extraction terminée, la fenêtre popup se ferme et vous en êtes informé par un message popup. Vous pouvez visualiser les données extraites en ouvrant le panneau Browse et les exporter en ouvrant le panneau Export data as CSV.
